Machine learning (ML) is a subset of computer science and artificial intelligence (AI) that uses data and algorithms to allow AI to imitate how people learn, gradually improving its accuracy. Within machine learning is a model called a generative adversarial network, also known as a neural network, specially designed to imitate the human brain’s structure and function.
This article tackles generative adversarial networks (or GAN for short), explaining the different types, how they work, their pros and cons, applications, and more. You will be amazed at what GANs can do. You can also learn more about them through an online AI and machine learning bootcamp.
So, what is a generative adversarial network?
What is a Generative Adversarial Network?
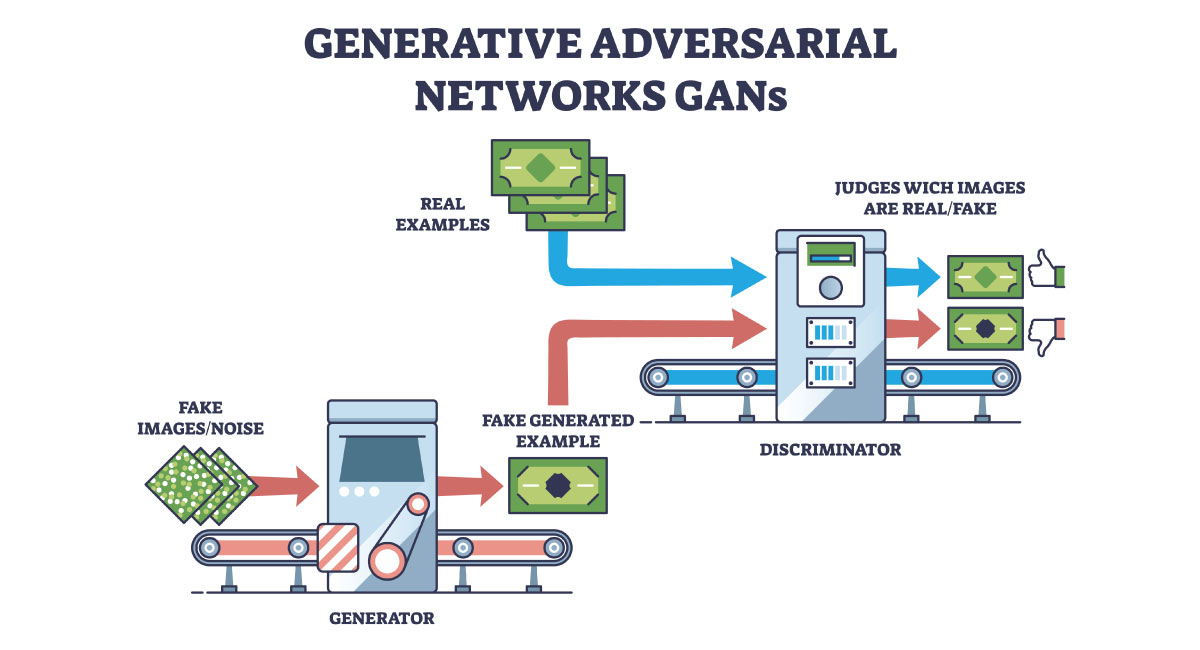
Generative Adversarial Networks are a robust class of neural networks used for unsupervised learning. They consist of two neural networks, called a Discriminator and a Generator, that compete against each other using deep learning methods to scrutinize, capture, and replicate the variations within a data set, thus generating more accurate predictions.
To summarize, GANs use adversarial training to produce artificial data that resembles actual data. They are a machine learning model that typically runs unsupervised and uses a cooperative zero-sum game framework to learn, so one party’s gain equals another party’s loss.
Let’s dive deeper into GAN machine learning by discussing what a discriminator and a generator are in general adversarial networks.
Also Read: Machine Learning in Healthcare: Applications, Use Cases, and Careers
What is a Generator?
Generators are convolutional neural networks that create false data that gets trained on the Discriminator to learn to generate plausible data. Generated examples and instances become negative training examples used by the Discriminator.
The Generator tries to fool the Discriminator, tasked with accurately distinguishing between created and genuine data, by creating random noise samples to train the Discriminator.
What is a Discriminator?
A Discriminator is a deconvolutional neural network that aims to identify which of the outputs it received was artificially created. The Discriminator identifies real data from false data created by the Generator by relying on training from two sources:
- Fake data instances produced by the Generator are used as negative examples
- Real data instances (e.g., images of people, animals, etc.) are used as positive examples
The Different Types of Generative Adversarial Networks
Vanilla GAN
This is the simplest GAN. The Generator and the Discriminator are basic multi-layer perceptrons. The algorithm is simple; it uses stochastic gradient descent to optimize the mathematical equation.
Conditional GAN (CGAN)
CGAN is a deep learning method that puts some conditional parameters into place.
- An additional parameter, called ‘y,’ is added to the Generator to generate the corresponding data
- Labels are put into the Discriminator’s input to help distinguish the actual data from the fake-generated data
Deep Convolutional GAN (DCGAN)
DCGAN is among the most popular and successful GAN implementations. It consists of ConvNets instead of multi-layer perceptrons.
- ConvNets are implemented without max pooling, which is replaced by convolutional stride
- The layers are not fully connected
Laplacian Pyramid GAN (LAPGAN)
This GAN is a linear, invertible image representation consisting of band-pass images spaced an octave apart and a low-frequency residual.
- This GAN approach uses multiple numbers of Generator and Discriminator networks and different pyramid levels
- This GAN approach is popular because it produces high-quality images. First, the image is down-sampled at each pyramid layer and then up-scaled at each layer in a backward pass. During this process, the image gains noise from the Conditional GAN at these layers until it returns to its original size.
Super Resolution GAN (SRGAN)
SRGAN is a design approach that uses a deep neural network alongside an adversarial network to produce higher-resolution images. This GAN is especially useful in optimally upscaling native low-res images to enhance their details, thereby minimizing errors in the process.
Also Read: What is Machine Learning? A Comprehensive Guide for Beginners
How Does a GAN work?
Here are the steps that summarize how a GAN works.
Initialization
In the first step, two neural networks are created: Generator (G) and Discriminator (D).
- G creates new data that resembles actual data, like images or text
- D acts like a critic, trying to discern between real data (from a training data set) and G’s generated data
Generator’s First Move
Next, G takes a random noise vector as its input. The noise vector contains random values and performs as G’s starting point for the creation process. G changes the noise vector into a new data sample using its internal layers and learned patterns, like a generated image.
Discriminator’s Turn
Next, D receives two kinds of inputs:
- Actual data samples pulled from the training data set
- The data samples G generated in the previous step. D’s job is to analyze each input and determine whether it’s actual data or something G created, generating a probability score between 0 and 1. A score of 1 means the data is probably real, while 0 suggests it’s false.
The Learning Process
Now comes the adversarial part:
- If D correctly identified the data as real (a score near 1) and the generated data as fake (a score closer to 0), both G and D get a small reward since they’re doing their jobs well.
- However, the point is to improve continuously, so if D keeps identifying everything correctly, it will only learn a little. Thus, the goal is for G to eventually trick D.
Generator’s Improvement
If D erroneously labels G’s creation as real (a score close to 1), G is on the right track. So, G receives a significant positive update, and D gets a penalty for being fooled. This feedback helps G generate more realistic data.
Discriminator’s Adaptation
But if D correctly identifies G’s fake data (a score close to 0), and G receives no reward, D’s discrimination abilities are further strengthened. This ongoing contest between G and D eventually refines both networks.
As training continues, G improves at generating realistic data, making it more difficult for D to discern the difference. Ideally, G becomes so good that D can’t reliably distinguish the real data from the fake. At this point, G is considered well-trained and can now be used to generate new, realistic data samples.
Outlining GAN Training Steps
- Define the problem
- Choose the GAN architecture
- Train the Discriminator on real data
- Create fake inputs for the Generator
- Train the Discriminator on the fake data
- Train the Generator with the Discriminator’s output
The Application of GANs
Here are some typical GAN applications.
- Image Synthesis and Generation. GANs are often used for picture synthesis and generation tasks. They could create fresh, lifelike pictures that imitate training data by learning the distribution that explains the data set. These generative networks facilitate the development of high-resolution photographs, lifelike avatars, and fresh artwork.
- Image-to-Image Translation. GANs can be used for problems involving image-to-image translation, such as converting an input picture from one domain to another while keeping its fundamental features intact. GANs can change pictures from day to night, turn drawings into realistic images, or change an image’s creative style.
- Text-to-Image Synthesis: GANs can produce pictures that translate a given description, such as a phrase or a caption. This application could impact how text-based instructions can produce realistic visual material.
- Data Augmentation. GANs can create synthetic data samples that augment present data and increase machine-learning models’ robustness and generalizability.
- Data Generation for Training. GANs can boost the quality and resolution of low-resolution images. By training on pairs of low and high-resolution images, they can generate high-resolution images from low-resolution inputs, allowing improved image quality in applications like satellite imaging, medical imaging, and video enhancement.
Also Read: Machine Learning Interview Questions & Answers
The Advantages and Disadvantages of GANs
GANs have pros and cons, so let’s check those out.
Advantages
- They can create realistic data samples
- They can continue to train themselves after the initial data input and learn from unlabeled data
- They can identify anomalies based on measurements that show how effectively the Generator and Discriminator can model the data
- They are versatile and can be applied to tasks such as image-to-image translation and synthesis
- They can generate high-quality, photorealistic results in image synthesis, music synthesis, video synthesis, and other tasks
Disadvantages
- It can be difficult to evaluate results depending on a given task’s complexity
- They can be challenging to train because large, varied, advanced data sets are needed
- They require considerable computational resources, making them slow to train
- They run the risks of instability, failure to converge, or mode collapse
Have You Considered Trying AI and ML Training?
You can learn more about AI and GANs by taking online training courses. This post graduate program in AI and ML is a high-engagement online learning experience that teaches Python, machine learning, natural language processing, and more.
Indeed.com reports that machine learning engineers earn an average annual salary of $166,001. So, if you’re looking for a well-paying, interesting career, take the first step with this great online program.
FAQs
Q: What is a generative adversarial network?
A: GANs use adversarial training to produce artificial data that resembles actual data. They are a machine learning model that typically runs unsupervised and uses a cooperative zero-sum game framework to learn.
Q: What is the purpose of GAN machine learning?
A: Generative Adversarial Networks are a powerful class of neural networks used for unsupervised learning.
Q: What is an example of a GAN?
A: Nvidia created new video game characters using GANs for the popular Final Fantasy XV game.
Q: Are GANs generative AI?
A: Yes, GANs are a type of generative AI.
Q: What are the advantages of generative adversarial networks?
A: Advantages include:
- They are helpful in many fields, like image generation, video prediction, and data synthesis
- They are unsupervised learning models that can train themselves after initial input
- They can create realistic data samples
You might also like to read:
How to Become an AI Architect: A Beginner’s Guide
How to Become a Robotics Engineer? A Comprehensive Guide
Machine Learning Engineer Job Description – A Beginner’s Guide





